Ethical Considerations in Gamification: Data Collection and Use
Privacy Concerns in the Gamified Landscape

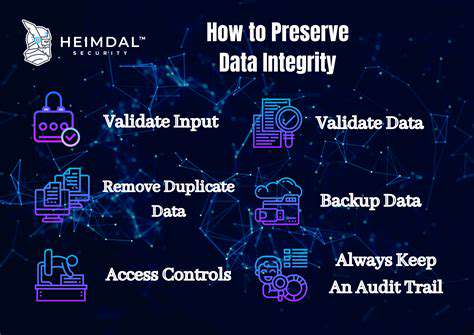
Data Collection and Usage
Modern gamified learning environments frequently gather extensive user data, tracking performance metrics, engagement with interactive elements, and even personal learning tendencies. The way this information is acquired, stored, and utilized has profound implications for individual privacy rights. Such detailed profiles might expose sensitive patterns in a learner's behavior, potentially creating unconscious preferences in subsequent educational interactions. Developers must maintain absolute clarity regarding their data practices to preserve user confidence.
Concerns about potential data mishandling or security breaches remain significant. Implementing enterprise-grade protection protocols and unambiguous privacy agreements forms the foundation of safeguarding sensitive user information. Learners deserve comprehensive control over their digital footprint, including straightforward options to review, modify, or permanently erase collected data.
Data Security and Protection
Protecting user information within gamified education systems demands rigorous attention. Security incidents could expose private details, resulting in serious confidentiality violations. Advanced encryption standards and meticulous permission structures become indispensable shields against unauthorized data exploitation. Conducting periodic security evaluations and identifying system vulnerabilities help maintain an impenetrable defense framework.
Anonymization strategies offer additional layers of protection against data exposure. The principle of collecting only essential information dramatically reduces potential risks associated with data storage. Establishing firm data lifecycle policies that specify retention periods further strengthens overall security posture.
Transparency and User Control
Building trust requires complete openness about information handling practices. Educational platforms incorporating game elements should present their data policies in clear, jargon-free language. Accessibility to these policies should require minimal effort, allowing users to quickly grasp what information gets tracked and why. Detailed explanations about data categories, processing methods, and access permissions foster informed decision-making.
Empowering users with data management tools proves equally critical. Individuals should possess straightforward mechanisms to inspect, update, or completely remove their stored information at any time. Intuitive interfaces for privacy preference adjustments and selective data sharing options encourage active participation in personal data governance.
Potential for Bias and Discrimination
Like all data-centric applications, gamified learning environments risk amplifying societal prejudices. Personalization algorithms might unintentionally cement existing stereotypes or create uneven learning opportunities across demographic groups. System architects must proactively examine potential discriminatory patterns during development phases to prevent systemic inequities.
Continuous assessment of platform impacts across diverse user segments helps maintain balanced educational outcomes. Incorporating multicultural viewpoints during design stages and performing routine bias audits on algorithms ensure more equitable learning experiences for all participants.
Bias and Discrimination in Algorithmic Design
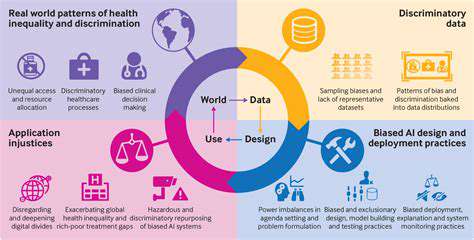
Understanding Algorithmic Bias
Computational bias emerges when machine learning systems absorb and reinforce societal prejudices present in their training data. These distortions can influence numerous decision-making processes, from financial approvals to employment screenings. Recognizing that these flaws originate in human-created datasets rather than the algorithms themselves represents the first step toward mitigation. Combatting algorithmic discrimination demands thorough examination of data provenance and anticipation of downstream effects.
Deploying computational models without rigorous bias screening may yield unjust or prejudiced results. Detecting and correcting these systemic flaws remains imperative for creating impartial automated systems. The objective extends beyond eliminating obvious discrimination to ensuring fundamentally just treatment for all individuals regardless of background.
Data Bias and its Impact
Skewed datasets represent the root cause of most computational prejudice. When training materials reflect historical or cultural biases, the resulting models inevitably reproduce these flaws. For instance, facial analysis systems trained primarily on certain ethnic groups demonstrate significantly reduced accuracy for underrepresented populations. This underscores the critical importance of comprehensive, demographically balanced training materials.
Data distortions can create substantial disparities in algorithmic outcomes. Mortgage approval systems influenced by biased historical data might systematically disadvantage particular communities, exacerbating existing economic divides. Meticulous data vetting and inclusion practices form the bedrock of ethical artificial intelligence development.
Bias in Machine Learning Models
Supervised learning architectures prove especially vulnerable to absorbing dataset prejudices. These models internalize and amplify any biases present in their training examples, potentially generating discriminatory predictions. Various machine learning approaches exhibit different susceptibility patterns, necessitating tailored correction methodologies.
Mitigating Algorithmic Bias
Multiple strategies exist for reducing computational prejudice, including rigorous data sourcing protocols, ensuring population-wide representation, and implementing bias-detection algorithms. Persistent performance monitoring allows timely identification and correction of emerging biases within operational systems.
Specialized fairness-enhancing algorithms and comprehensive audit frameworks help identify and minimize model distortions. Bias reduction constitutes an iterative process requiring sustained commitment rather than one-time fixes.
The Role of Human Oversight
Continuous human supervision remains indispensable throughout the algorithm lifecycle. Subject matter experts must participate in system design, training validation, and outcome evaluation to detect potential discrimination. This includes verifying training data diversity and ensuring ethical application of predictive models.
Human judgment incorporates contextual understanding and moral considerations that pure computational systems frequently miss. This oversight proves vital for developing systems that balance accuracy with fundamental fairness principles.
Ethical Considerations in AI Development
Artificial intelligence implementation raises profound questions regarding justice, explainability, and responsibility. Recognizing discrimination risks represents a prerequisite for creating inclusive technological solutions rather than exclusionary systems. Proactive measures must precede widespread deployment to prevent institutionalizing harmful biases.
Algorithmic prejudice can generate widespread consequences across social and economic domains. Prioritizing ethical frameworks throughout development pipelines ensures responsible innovation that serves all community members equitably.
Regulatory and Legal Frameworks
Comprehensive governance structures must evolve to address algorithmic discrimination challenges. These should establish standards for ethical data practices, model development protocols, and accountability mechanisms. Clear directives for responsible artificial intelligence deployment help minimize potential societal harm.
Legal frameworks should demonstrate adaptability to keep pace with rapid technological advancement. Such dynamic regulation ensures computational systems respect universal rights while promoting just outcomes across diverse populations.
Read more about Ethical Considerations in Gamification: Data Collection and Use










Hot Recommendations
- Attribution Modeling in Google Analytics: Credit Where It's Due
- Understanding Statistical Significance in A/B Testing
- Future Proofing Your Brand in the Digital Landscape
- Measuring CTV Ad Performance: Key Metrics
- Negative Keywords: Preventing Wasted Ad Spend
- Building Local Citations: Essential for Local SEO
- Responsive Design for Mobile Devices: A Practical Guide
- Mobile First Web Design: Ensuring a Seamless User Experience
- Understanding Your Competitors' Digital Marketing Strategies
- Google Display Network: Reaching a Broader Audience